Machine Learning For Sentiment Analysis
Introduction to Sentiment Analysis
A sentiment is a concept or feeling that someone expresses in words. With that in mind, sentiment evaluation is the process of predicting/extracting those ideas or feelings. We want to understand if the sentiment of a piece of writing is positive, negative, or neutral. precisely what we imply through positive/negative sentiment depends on the problem we’re looking to resolve.
You Must have given feedback to e-commerce websites about their product. That’s where sentiment analysis comes into play.

Sentiment analysis is the technique of using natural language processing, textual content analysis, and statistics to research customer sentiment. The pleasant groups apprehend the sentiment of their clients — what humans are pronouncing, how they’re saying it, and what they imply. client sentiment can be determined in tweets, feedback, critiques, or other places where people mention your brand. Sentiment evaluation is the area of understanding these emotions with software programs, and it’s a must-recognize for developers and commercial enterprise leaders in a contemporary workplace.
What is Sentiment Analysis Used for?
In today’s environment where we suffer from data overload (although this may mean better or deeper understanding), companies may have a lot of customer feedback collected. For humans, however, it is still difficult to process it in person without any form of error or bias.
In many cases, well-meaning companies find themselves unaware of it. You know you need the information to inform your decision-making. And you know you don’t have them. But you do not know how to find them.
The emotional analysis provides answers to the issues that are most important Because emotional analysis can be done automatically, decisions can be made based on a significant amount of data instead of an obvious sense that is not always right.
Because of these things sentimental analysis is being used at various places, like for brand monitoring, customer service, market research and analysis, and at various places.
How Sentiment Analysis is done?
There are two basic types for sentiment analysis
- Rule-based sentiment analysis
- Machine Learning-based Sentiment Analysis
Confused? Let’s check each one by one!
Rule-Based Sentiment Analysis
This is a realistic way to analyze the text without training or using machine learning models. The result of this approach is to create a set of rules based on the text labeled positive/negative/neutral. These rules are also known as dictionaries. Therefore, the Law-based approach is called the Lexicon-based approach.
Widely used lexicon-based approaches are TextBlob, VADER, SentiWordNet.
TextBlob
TextBlob is a python library for Natural Language Processing (NLP).TextBlob actively uses Natural Language ToolKit (NLTK) to achieve its tasks. For lexicon-based approaches, a sentiment is defined by its semantic orientation and the intensity of each word in the sentence. This requires a pre-defined dictionary classifying negative and positive words. Generally, a text message will be represented by a bag of words. After assigning individual scores to all the words, the final sentiment is calculated by some pooling operation like taking an average of all the sentiments.
TextBlob returns the polarity and subjectivity of a sentence. Polarity lies between [-1,1], -1 defines a negative sentiment and 1 defines a positive sentiment. Negation words reverse the polarity. TextBlob has semantic labels that help with fine-grained analysis. For example — emoticons, exclamation marks, emojis, etc. Subjectivity lies between [0,1]. Subjectivity quantifies the amount of personal opinion and factual information contained in the text. The higher subjectivity means that the text contains personal opinions rather than factual information. TextBlob has one more parameter — intensity. TextBlob calculates subjectivity by looking at the ‘intensity’. Intensity determines if a word modifies the next word. For English, adverbs are used as modifiers (‘very good’).
VADER
VADER (Valence Aware Dictionary for Sentiment Reasoning) is a model used to analyze sensitive text emotions in both polarities (good/bad) and emotional (strength) emotion. It is available in the NLTK package and can be used directly on labeled text data.
VADER’s emotional analysis is based on a dictionary that shows the lexical features of emotional stability known as emotional points. Text sensitivity can be obtained by summarizing the intensity of each word in the text.
For example- Words like ‘love’, ‘enjoy’, ‘rejoice’, ‘love’ all convey positive emotions. And VADER is wise enough to understand the basic meaning of these words, such as “did not like” as a negative statement. It also understands capital emphasis and punctuation, such as “HAPPY”.
Machine Learning-Based Sentiment Analysis
Here one has to train a model to recognize the sentiment primarily based on the phrases and their order the usage of a sentiment-labeled training set. This technique depends largely on the kind of algorithm and the quality of the training data used.
Let’s look at an example that involves stock trading. One takes news headlines and narrows them to lines that mention the particular organization that we are interested in and then gauge the polarity of the sentiment inside the text.
One way to make this method fit other sorts of problems is to measure polarity across different dimensions. you could study specific emotions. How irritated was the individual when they were writing the text? How much worry is conveyed in the text?
Now For clear understanding, we will see in detail how can we use Machine Learning Algorithms for Sentiment Analysis.
There are a number of complex strategies and algorithms used to instruct and train equipment to perform emotional analysis. There is good and bad in each other. However, when used together, they can produce extraordinary results. Below are some of the most widely used algorithms.
Linear Regression
Linearity is a mathematical algorithm used to predict the value of Y, given the X-values. Using machine learning, data sets are scanned to show relationships. The relationship is then placed next to the X / Y axis, with a straight line passing through them to predict further relationships.
The dropline calculates how the X input (words and phrases) corresponds to the Y output (polarity). This will determine where words and phrases fall within the range of polarity from “really good” to “really bad” and everywhere in between.
Support Vector Machine
The vector support machine is another moderated machine learning module, similar to the reversal of the line but more advanced. SVM uses algorithms to train and separate text within our emotional polarity model, taking action beyond X / Y speculation.
For a simple visual explanation, we will use two markers: red and blue, which have two data elements: X and Y. We will train our classifier to produce red or blue X / Y coordinate.
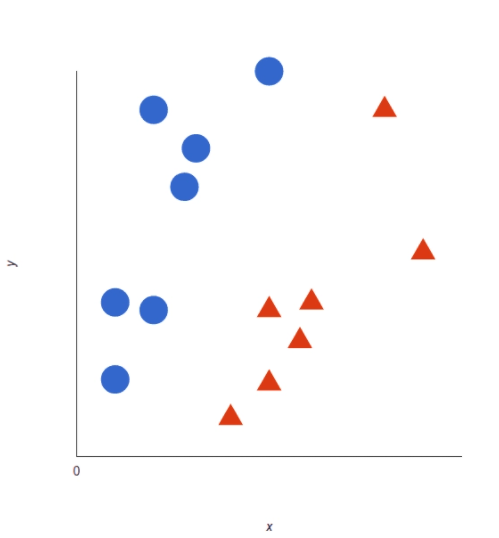
SVM then provides us with a hyperplane that better separates tags. On both sides, this is simply a line (like the back of a line). Anything on one side of the line is red and anything on the other side is blue. For emotional analysis, this will be both positive and negative.
To increase machine learning, the leading hyperplane is the one that has the largest distance between each marker:

However, as data sets become more complex, it may not be possible to draw a single line to divide data into two categories:
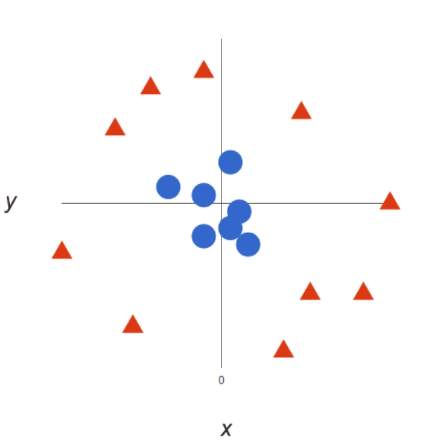
With the use of SVM, the more complex the data, the more accurate the prediction will be. Consider the above in three dimensions, plus the Z-axis, so it becomes a circle.
The map has been restored to two dimensions with a moving hyperplane, it looks like this:
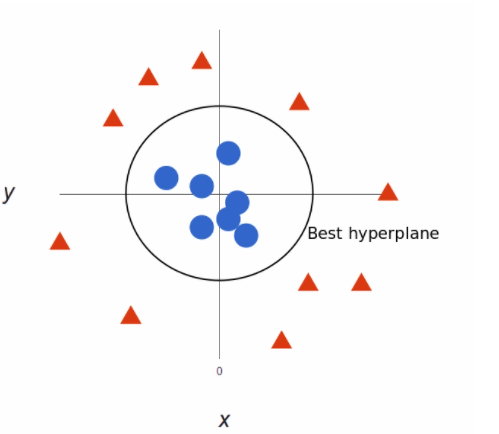
Simply put, SVM allows for more accurate machine reading because it is more diverse.
Naive-Bayes
Naive Bayes is the simplest and fastest classification algorithm for a large chunk of data. In various applications such as spam filtering, text classification, sentiment analysis, and recommendation systems, Naive Bayes classifier is used successfully. It uses the Bayes probability theorem for unknown class prediction.
Naive Bayes algorithm intuition
The Bayes theorem is used by the Naive Bayes Classifier to forecast membership probabilities for each class, such as the likelihood that a given record or data point belongs to that class. The most likely class is defined as the one having the highest probability. The Maximum A Posteriori (MAP) is another name for this.
For a hypothesis with two occurrences A and B, the MAP is
MAP (A) = max (P (A | B)) = max (P (B | A) * P (A))/P (B) = max (P (B | A) * P (A)
Naïve Bayes classifier is one of the supervised classification techniques which classifies the text/sentence that belongs to a particular class. It is the probabilistic algorithm which calculates the probability of each word in the text/sentence and the word with the highest probability is considered as output.
- Let us consider a document a
- A document a with a set of classes B = { b1, b2, … , bn}
- Consider a training set having m documents that are pre-determined that belong to a particular class.
Now we train our classification algorithm using this training set and we get trained classifiers. By using this trained classifier we can classify the new document.
While standard naive Bayes text classification can work well for sentiment analysis, some small changes are generally employed that improve performance.
First, for sentiment classification and a number of other text classification tasks, whether a word occurs or not seems to matter more than its frequency. Thus it often improves performance to clip the word counts in each document at b1. This variant is called binary NB multinomial naive Bayes or binary NB.
Deep Learning
Deep learning is a subfield of machine learning that aims to calculate data as the human brain uses “artificial neural networks.”
Deep learning is hierarchical machine learning. In other words, It is multi-level and allows a machine to automatically ‘chain’ a number of human-created processes together. By allowing multiple algorithms to be used progressively while moving from step to step, deep learning is able to solve complex problems in the same way humans do.
Conclusion
These are just some widely used machine learning algorithms. There are many Machine learning algorithms that can be used with sentiment analysis. Even two different algorithms can be combined and a person can work on that new algorithm which is also termed as hybrid sentiment analysis.
❤ ❤ Thanks for reading this article ❤❤
If I got something wrong? Let me know in the comments. I would love to improve.
Clap 👏 If this article helps you.
